Olympics Data Engineering Project With Azure DevOps
- Jesse Pepple
- Oct 3, 2025
- 8 min read

Updated: Jan 8
This project focused on building an end-to-end Azure & Databricks data pipeline using the Olympics 2024 dataset. I began by provisioning the required Azure resources and designing the solution around a Medallion Architecture (Bronze → Silver → Gold) to ensure scalability, data quality, and reliability.
Data was ingested using Azure Data Factory (ADF) and stored in Azure Data Lake Storage, establishing the raw Bronze layer. From there, I applied data governance through Unity Catalog, ensuring secure, centralized access and proper organization of the datasets.
For transformations, I leveraged Delta Live Tables (DLT) in Databricks. Here, I implemented Change Data Capture (CDC) to manage Slowly Changing Dimensions (SCD Type 1), ensuring that the dataset stayed consistent and up to date with incoming changes. This process allowed me to handle both initial loads and incremental updates, showcasing efficiency and automation within the pipeline.
The curated Gold layer was then delivered to both Databricks SQL Warehouse and Azure Synapse Analytics, enabling advanced analytics and reporting. This provided analysts with flexible access options and optimized datasets ready for business intelligence tools such as Power BI.
By the end of the project, I had implemented a robust, scalable, and governed data pipeline that demonstrated best practices across ingestion, transformation, governance, and delivery within the Azure and Databricks ecosystem.
Azure Services:
Azure Databricks
Azure Data Factory (ADF)
Azure Data Lake Storage (ADLS Gen2)
Azure Synapse Analytics
Azure DevOps (for version control and CI/CD)
Databricks Components:
Delta Lake & Delta Tables
Unity Catalog (governance)
Delta Live Tables (DLT)
CDC (Change Data Capture) for SCD Type 1
Databricks SQL Warehouse
Languages & Tools:
Python (PySpark / notebooks)
SQL
Overall Project Impact
End-to-End Automation: Bronze → Silver → Gold with CDC + SCD Type 1 handling
Governance: Unity Catalog ensures secure, auditable, and governed data assets
Incremental Loading: Automatic detection and ingestion of new data → reduces processing costs and runtime
Business Value: Analysts and data scientists can now access clean, curated, and ready-to-use datasets for reporting and advanced analytics
Portfolio Highlight: Showcases cloud data engineering skills, CI/CD, and modern ETL design with Delta Lake
PROJECT OVERVIEW

The Azure Olympics 2024 Data Engineering Project is an end-to-end data pipeline built on Azure and Databricks using the Olympics 2024 dataset. The project was orchestrated and tracked in Azure DevOps, where I implemented CI/CD pipelines to ensure automated deployments, reproducibility, and version control across the solution.
For data ingestion, I used Azure Data Factory (ADF) to bring in the raw dataset, storing it in the Bronze layer of Azure Data Lake Storage, following the Medallion Architecture (Bronze → Silver → Gold). Governance and security were enforced using Unity Catalog, which provided access control, lineage tracking, and centralized governance for all datasets.
The transformation stage took place in Azure Databricks, where I cleaned and refined the data into the Silver and Gold layers. For the Gold layer specifically, I implemented Delta Live Tables (DLT) as an automated ETL framework, which streamlined orchestration and ensured data quality checks were applied at each step. To handle data changes effectively, I integrated the Change Data Capture (CDC) API and applied Slowly Changing Dimensions (SCD Type 1) to the athletes table, ensuring that updates were reflected seamlessly in the curated datasets.
For data delivery and consumption, I designed curated streaming pipelines and loaded the refined datasets into both Databricks SQL Warehouse and Azure Synapse Analytics, providing flexibility for downstream business intelligence and reporting. Analysts could now access the same high-quality dataset through multiple platforms, including Power BI, for real-time insights.
Creating And Ingesting Olympics Source Data with ADF and Azure Devops
Before ingesting any data, I first set up Azure DevOps and created a dedicated Git branch for the project. This allowed me to establish version control, collaboration readiness, and CI/CD pipelines from the very beginning, ensuring a streamlined and reproducible deployment process throughout the project lifecycle.




Now that the dedicated branch was created in Azure DevOps, the next step was to ingest the Olympics 2024 dataset from the source system. Now next up is time for ingesting Data with our ADF branch
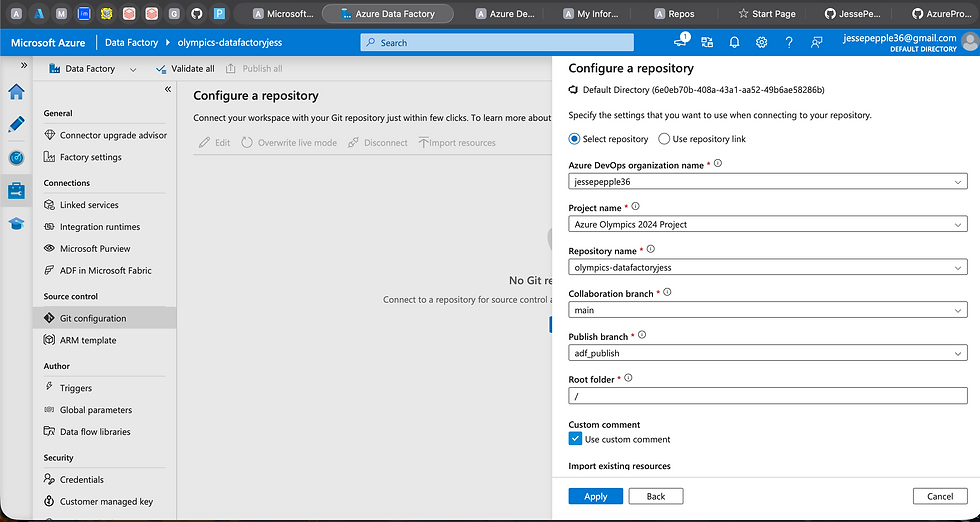

The data ingestion pipeline was executed successfully, with the ForEach activity orchestrating the ingestion of multiple source files dynamically. To ensure flexibility and scalability, I combined the Lookup activity (to retrieve file metadata) with ForEach, allowing the pipeline to loop through and ingest each dataset seamlessly. Once ingestion was complete and the raw data was securely stored in the Bronze layer of Azure Data Lake, I returned to Azure DevOps to review my commits and validate that all changes were properly version-tracked. This step reinforced good DevOps practices, ensuring that my pipelines and configurations remained reproducible, auditable, and aligned with the CI/CD workflow.



Goal: Efficiently ingest Olympics 2024 datasets into the Bronze (raw) layer of Azure Data Lake following Medallion Architecture.
KPIs & Metrics:
Data Volume Ingested: Multiple tables ingested successfully, including Athletes, Events, and Medals
Incremental Loading: Spark Structured Streaming + checkpointing → new data automatically processed without reprocessing existing rows
Automation: ForEach activity with parameterized notebooks → ingestion of multiple datasets in a single run
Data Quality: Initial raw ingestion validated; no missing or corrupted files
Result Statement:
Implemented a robust and automated incremental ingestion pipeline, ensuring raw datasets are efficiently loaded into the Bronze layer while maintaining data fidelity.
Phase 2 Transformations
With Unity Catalog already enabled across my Databricks workspace, the setup for governance and transformation was straightforward. I began by creating a dedicated catalog to logically organize my data assets, ensuring clear separation between environments and datasets. Next, I defined external locations mapped to the Bronze containers in Azure Data Lake Storage, which allowed me to securely reference the ingested raw data. This step not only streamlined access management but also provided centralized governance, auditing, and lineage tracking, ensuring that the data flowing through the pipeline remained both secure and compliant. With the governance layer in place, I was ready to progress into transformations in the Silver layer, where raw data would be cleaned, standardized, and prepared for downstream processing.


With the external locations configured, I began reading the Olympics datasets into Databricks and applying the first wave of transformations to prepare them for the Silver and Gold layers. In the Silver layer, the focus was on data quality and consistency—removing duplicates, standardizing formats, enforcing schemas, and handling missing values. This ensured the data was clean and reliable while retaining its granular details.
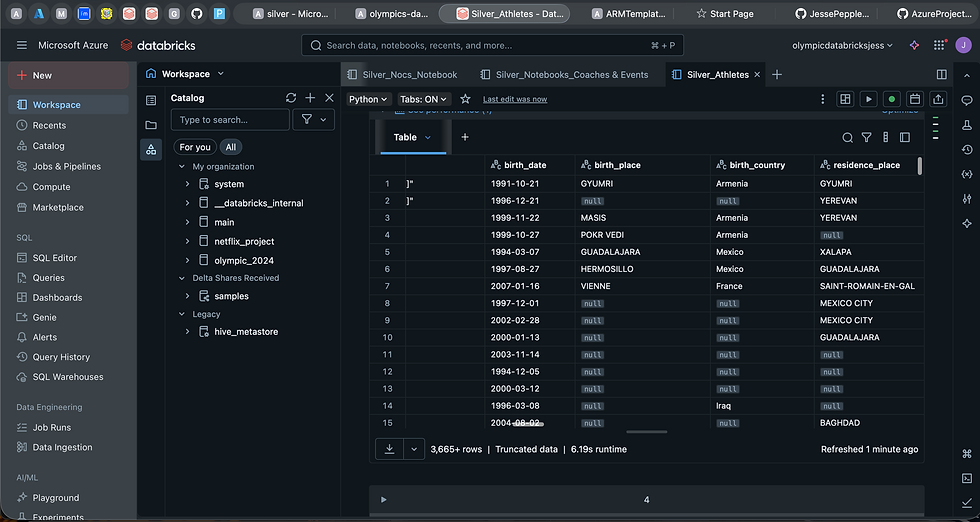
Goal: Clean, enrich, and prepare datasets for curated analysis.
KPIs & Metrics:
Unity Catalog Governance: Access control and lineage enabled for all Bronze/Silver/Gold datasets
Silver Layer Preparation: Cleaned and enriched datasets using PySpark transformations
CDC for SCD Type 1: Delta Live Tables applied apply_changes() for the Athletes table
Data Quality Checks: Null values and schema inconsistencies identified and corrected
Result Statement:
Processed and enriched Silver-layer datasets while automating SCD Type 1 handling, ensuring high-quality, analyst-ready data.
SERVING- GOLD LAYER(DLT & CDC CAPTURE)
After transforming the data, I read and wrote it back to the Data Lake, saving the cleaned datasets as Delta Tables within Databricks. The next stage focused on serving the final curated datasets for analytics and reporting. To achieve this, I leveraged Delta Live Tables (DLT), a powerful declarative ETL framework that allowed me to define data quality rules, automate refreshes, and simplify orchestration.
Within DLT, I applied the CDC apply_changes function to implement Slowly Changing Dimensions (SCD Type 1) for the athletes master table. This ensured that whenever new updates were ingested, the most recent records would overwrite older values seamlessly, keeping the dataset accurate and up to date. Additionally, I introduced expectations within my DLT pipelines, particularly for handling Null values in critical fields. This proactive validation step improved reliability, ensuring that only data meeting the quality standards was promoted into the Gold layer.
By combining CDC with DLT, I not only automated incremental updates but also enforced governance and quality, resulting in a scalable, production-ready pipeline.

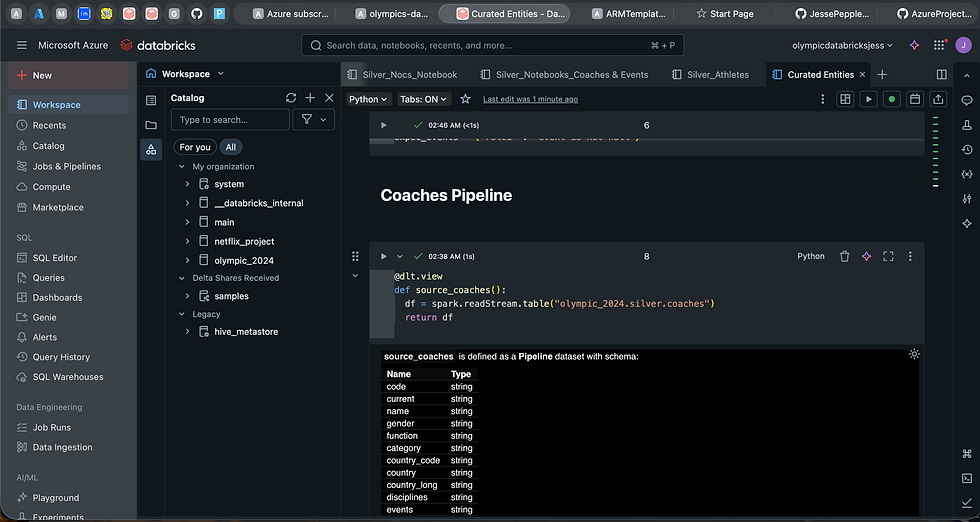

Final Pipeline
Thanks to Delta Live Tables (DLT), much of the pipeline orchestration became fully automated. Instead of manually managing refresh cycles, all I needed to do was define data quality expectations to validate the integrity of my datasets and confirm that the Slowly Changing Dimensions (SCD Type 1) logic (via upserts) was implemented correctly. This automation significantly reduced operational overhead, while ensuring that updates to the athletes master table and other curated datasets were handled seamlessly and consistently.


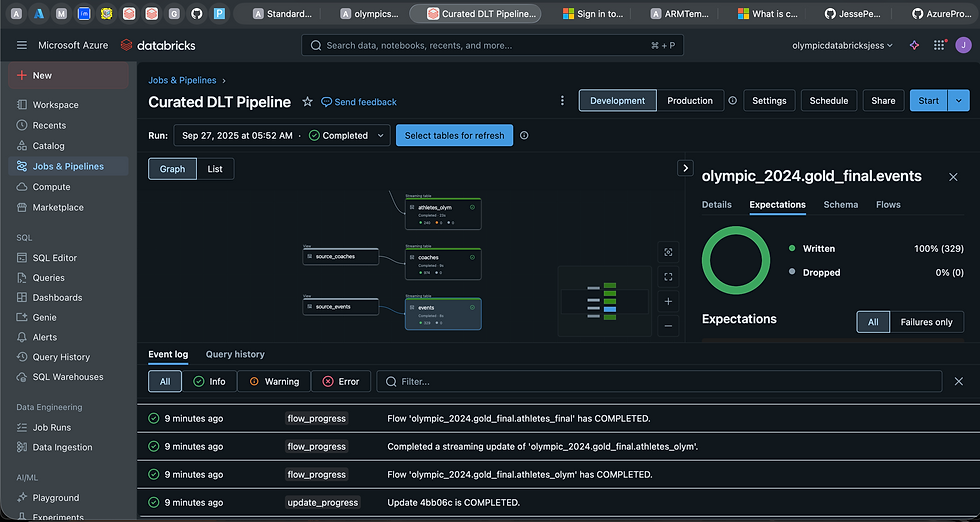


With all Data Quality Checks successfully passed, the curated Olympics 2024 datasets were verified and ready for consumption. Analysts and data scientists could now confidently access the cleaned, validated, and business-ready data for reporting, visualization, and advanced analytics. This final step marked the successful completion of the end-to-end pipeline, demonstrating a robust, governed, and fully automated data engineering workflow.
Goal: Deliver Gold layer datasets ready for analytics, with historical data tracked efficiently.
KPIs & Metrics:
Delta Live Tables (DLT): Automated ETL pipelines for Gold layer
SCD Type 1: CDC applied to master tables → UPSERT logic maintained historical changes
Data Quality Checks: All tables passed validation → no dropped or duplicate records
Tables Served: Gold-layer tables ready for analytics in Databricks SQL Warehouse and Synapse Analytics
Result Statement:
Delivered fully curated, quality-assured Gold-layer datasets using automated ETL and CDC for SCD Type 1, providing a reliable foundation for reporting and analytics.
Loading Our Curated Data In SQL Warehousing In Databricks
For reporting and validation, I tested the curated Olympics 2024 datasets using the Serverless SQL Warehouse in Databricks. This allowed me to simulate the type of queries analysts would run, ensuring the datasets were accurate, well-structured, and ready for analysis and visualization. By performing these checks, I confirmed that the pipeline reliably delivered business-ready, high-quality data for downstream reporting and decision-making.




BI Partner Connect
Thanks to Databricks Partner Connect, I provided the BI connector to the Data Analysts, enabling them to directly query and visualize the cleaned Olympics 2024 data in Power BI. This approach allowed analysts to access and explore the datasets without relying on the SQL Data Warehouse, streamlining reporting and providing flexible, real-time access to business-ready data.
Github Link:
Now that we are at the end of my project walkthrough below is the link to my Olympics Data Github repository containing the codes, notebooks and details about our project
Loading In Synapse
To provide additional flexibility for analysts, I loaded the curated Olympics 2024 datasets into Azure Synapse Analytics using the OPENROWSET() function. This approach enabled the final datasets stored in the Data Lake to be directly queried in Synapse. My favourite function tbf😅.







In my project, I chose to use views instead of tables in Synapse for the presentation layer because they provide abstraction and simplicity, hiding the complexity of the underlying raw and transformed data while making it easier for analysts to query. Views are lightweight and flexible, allowing quick updates to schema or business logic without the need to reload or duplicate data. This aligns with best practices in modern data architectures, where tables handle persistence at the raw and curated layers, while views expose clean, business-friendly models to end users. By doing this, I was able to balance performance with usability, showcasing how Synapse can still leverage optimized underlying storage while offering analyst-ready models. For my GitHub portfolio, using views also better communicates design thinking, highlighting my ability to present data in a way that aligns with real-world reporting and analytics needs rather than just displaying raw storage as soon after completion of project resource group will be deleted, although in production and future portfolio project this would be a different case as there are major instance in data loading in Synapse Workspace, in which I will demonstrate my skills in creating and presenting external tables.
Data Delivery & BI Integration
Goal: Make curated datasets accessible for business intelligence and reporting.
KPIs & Metrics:
Databricks SQL Warehouse: Curated datasets tested via SQL queries and dashboards
Synapse Analytics: External tables and views created using OPENROWSET → optimized for analyst consumption
Views vs Tables: Lightweight views abstract raw complexity → analysts can query business-ready data directly
BI Partner Connect: Power BI connector enabled → Analysts accessed and visualized data without relying on SQL Warehouse
Result Statement:
Delivered curated datasets to Databricks SQL Warehouse and Azure Synapse Analytics with analyst-ready views, enabling flexible and efficient BI reporting.



Comments